


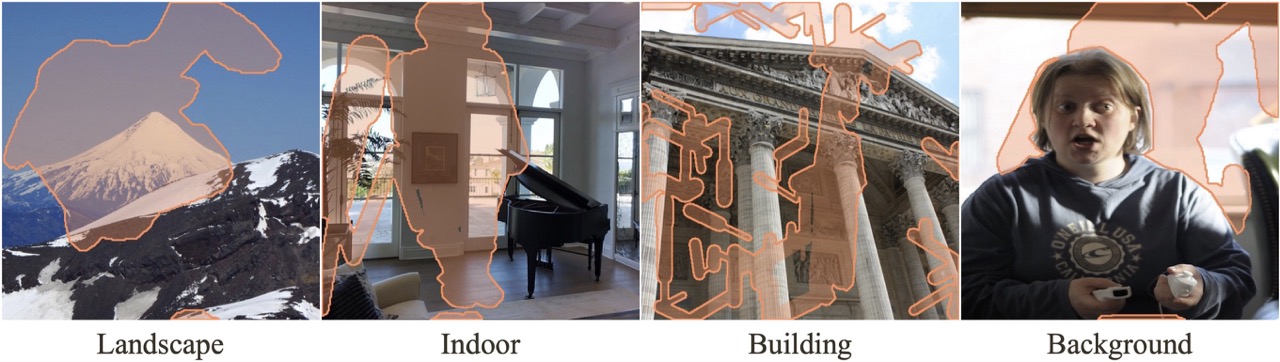
To validate across different domains and mask styles, we construct a evaluation dataset, dubbed as MISATO, from Matterport3D, Flickr-Landscape,MegaDepth, and COCO 2014 to handle indoor, outdoor, building and background inpainting, respectively. We select 500 representative examples of size 512x512 and 1024x1024 from each dataset, forming a total of 2,000 testing examples.
Please refer to our paper(preprint) for more details.

ASUKA and MISATO :)
