SeMani: Semantic Manipulation for
Entity-Level Text-Guided Image Manipulation
[Papers: CVPR22 oral, journal extension (Full-size PDF)]
[code]
[bib]
@inproceedings{wang2022manitrans,
author = {Wang, Jianan and Lu, Guansong and Xu, Hang and Li, Zhenguo and Xu, Chunjing and Fu, Yanwei},
title = {ManiTrans: Entity-Level Text-Guided Image Manipulation via Token-Wise Semantic Alignment and Generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
@article{wang2023entitylevel,
title={Entity-Level Text-Guided Image Manipulation},
author={Wang, Yikai and Wang, Jianan and Lu, Guansong and Xu, Hang and Li, Zhenguo and Zhang, Wei and Fu, Yanwei},
year={2023},
journal={arXiv preprint arXiv:2302.11383},
}
Introduction
Entity-Level Text-Guided Image Manipulation (eL-TGIM) is a novel task of text-guided image manipulation on the entity level in the real world. eL-TGIM takes as inputs the entity prompt word, the target text description, and the original image from the real world. The following illustration provides a visual representation of eL-TGIM.
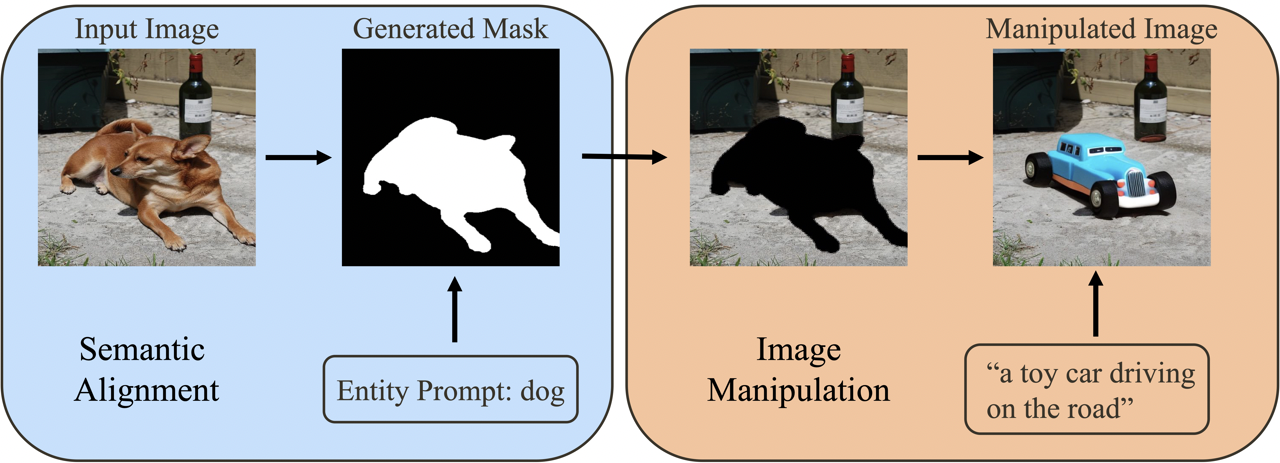
eL-TGIM imposes three basic requirements,
- To edit the entity consistent with the text descriptions;
- To preserve the entity-irrelevant regions;
- To merge the manipulated entity into the image naturally.

Muse and Imagic can create new entity-irrelevant regions instead of preserve these regions, while DALLE2 needs a user-provided mask to perform image manipulation and can only generate square images. As a result, it is not straightforward to apply existing editors to eL-TGIM.
Framework
To address eL-TGIM, we propose a framework called SeMani (Semantic Manipulation of real-world images), which consists of two phases: semantic alignment and image manipulation. In the semantic alignment phase, SeMani utilizes a semantic alignment module to identify the regions of the image that need to be manipulated. In the image manipulation phase, SeMani employs a generative model to create new images based on the entity-irrelevant regions and target descriptions. Below is an illustration of SeMani.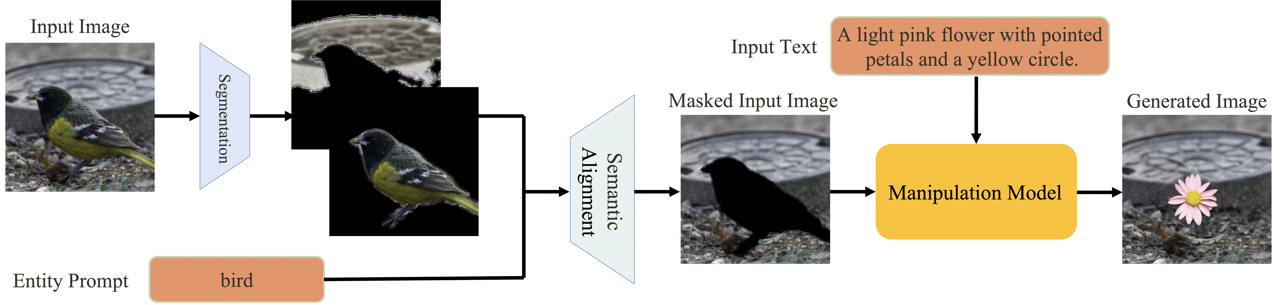
To implement SeMani, we resort to two popular perspectives for viewing images: discrete and continuous. The discrete perspective draws inspiration from auto-regressive transformers, while the continuous perspective is inspired by denoising diffusion probabilistic models. These perspectives give rise to two variants of SeMani: SeMani-Trans and SeMani-Diff. Each variant of SeMani uses specific architectures and generation processes. SeMani can perform manipulation on multiple objects either simultaneously or sequentially, as shown below.

For details about SeMani-Trans and SeMani-Diff, please refer to our paper.
Experiments
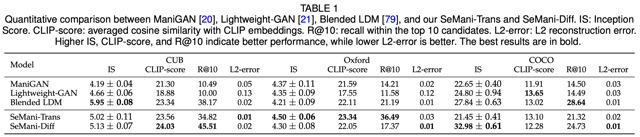
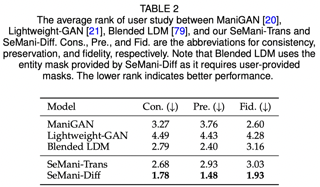
We conducted experiments on CUB, Oxford, and COCO datasets, results are shown in below.

We also design an interface for using SeMani.
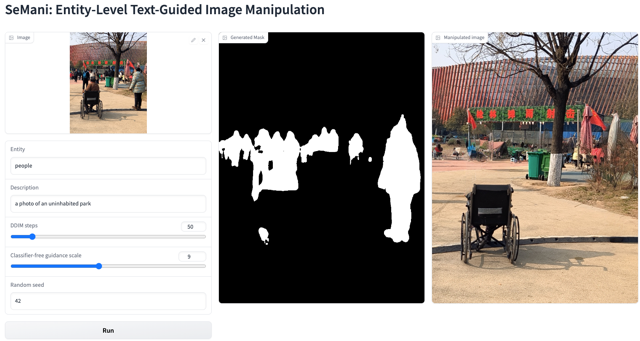
Please refer to our papers(CVPR22 oral, journal extension) for more details.